Normalizing Flows are based on the change of variables formula. To understand how this formula works, consider a set of samples $x$ drawn from a normal distribution and we have a smooth and invertible function $f$. I denote the samples $x$ before transformation as $x_0$ and those after transformation as $x_{1}$. Now these samples are distributed according to a new distribution $p_{1}$. We can compute what this new distribution looks like by applying the conservation of probability mass which states that the probability of an event occurring in interval $|dx_{1}|$ must equal the probability of event occurring in interval $|dx_{0}|$.
\[p_{1}(x_{1})|dx_{1}| = p_{0}(x_{0})|dx_{0}|\]Further rearranging the terms and substituting $x_0 = f^{-1}(x_1)$
\[p_{1}(x_{1}) = p_{0}(x_{0}) \frac{|dx_{0}|}{|dx_{1}|}\] \[p_{1}(x_{1}) = p_{0}(f^{-1}(x_{1})) \frac{|df^{-1}(x_{1})|}{|dx_{1}|}\]The above equation holds for the 1D case but when dealing with multi-dimensional probability distributions we compute the determinant
\[p_{1}(x_{1}) = p_{0}(f^{-1}(x_{1})) | \det \frac{df^{-1}(x_{1})}{dx_{1}} |\]If $f(x)$ is a linear transformation i.e $ x_1 = f(x_0) = A x_0 $ then the change of variables can be written as :
\[p_{1}(x_{1}) = p_{0}(f^{-1}(x_{1})) | \det A^{-1} |\]Lets look at an example to see this formula in action :
# Parameters for p0 dist
mu = 0
sigma = 0.5
rng = np.random.default_rng(seed=seed)
num_bins = 50
samples = 1000
# I use a normal distribution for p0
x0_samples = rng.normal(mu, sigma, size=(samples, 1))
plt.figure(figsize=(5, 3))
plt.hist(x0_samples, bins=num_bins, label='Empirical p0 dist')
plt.legend()
plt.show()
# Defining a smooth and invertible function f
f = lambda x: np.exp(x) # x**2
f_inv = lambda x : np.log(x) # np.sqrt(x)
df_invdx = lambda x : 1/x # 0.5*(x**(-0.5))
# Generating transformed samples
x1_samples = f(x0_samples)
plt.figure(figsize=(5, 3))
count, p1_bins, ignored = plt.hist(x1_samples, bins=num_bins, label='Empirical p1 dist')
plt.legend()
plt.show()
def p0(x, mu=0, sigma=1):
return (1/np.sqrt(2*np.pi*sigma**2))*np.exp(-((x - mu)**2)/(2*sigma**2))
def logp0(x, mu=0, sigma=1):
return np.log(1/np.sqrt(2*np.pi*sigma**2)) - ((x - mu)**2)/(2*sigma**2)
plt.figure(figsize=(5, 3))
plt.hist(x1_samples, bins=num_bins, density=True, alpha=0.6, color='skyblue', label='Empirical p1 dist')
# Plot theoretical PDF using Change of Variables
plot_range = np.linspace(0.1, np.max(p1_bins), samples)
p1 = p0(f_inv(plot_range), mu, sigma) * np.abs(df_invdx(plot_range))
plt.plot(plot_range, p1, 'r-', lw=2, label='Theoretical (Change of Variables)')
plt.legend()
Composing multiple bijections
Normalizing flows are able to learn complex distributions starting from simple priors by applying a sequence of invertible transformations whose Jacobians are much more efficient to compute than one single complex invertible mapping.
\[x_{0} \xrightarrow{f_{1}} x_{1} \xrightarrow{f_{2}} \dots \xrightarrow{f_{L}} x_{L}\]Each $f_{k}$ for $k \in \{k=1 \dots L\}$ follows a smooth bijection. If the initial samples $x_{0}$ follows the distribution $p_{0}$ then, each subsequent sample follows distributions $p_{1}$ to $p_{L}$. The transformation path of the samples is called flow while the path traced by the distributions is called the normalizing flow. The change of variables formula can be applied to compute the theoretical distribution at each stage :
\[p_{k}(x_{k}) = p_{k-1}(x_{k-1})| \det \frac{\partial f_{k}(x_{k-1})}{\partial x_{k-1}}|^{-1}\] \[p_{k}(x_{k}) = p_{\rm{prior}}(x_{0}) \prod_{i=0}^{L-1} | \det \frac{\partial f_{k}(x_{k})}{\partial x_{k}}|^{-1}\] \[\log p_{k}(x_{k}) = \log p_{\rm{prior}}(x_{0}) - \sum_{i=1}^{L-1} \log | \det \frac{\partial f_{k}(x_{k})}{\partial x_{k}}|\]The expression reflects how much each transformation stretches or contracts volume as determined by the Jacobian.
# Example of multiple bijections
x2_samples = f(x1_samples)
plt.figure(figsize=(5, 3))
count, p2_bins, ignored = plt.hist(x2_samples, bins=num_bins, label='Empirical p2 dist')
plt.legend()
plt.show()
plt.figure(figsize=(5, 3))
plt.hist(x2_samples, bins=num_bins, density=True, alpha=0.6, color='skyblue', label='Empirical p2 dist')
# Plot theoretical PDF using Change of Variables
plot_range = np.linspace(0.1, np.max(p2_bins), samples)
p2 = p0(f_inv(plot_range), mu, sigma) * np.abs(df_invdx(plot_range)) * np.abs(df_invdx(plot_range))
plt.plot(plot_range, p2, 'b-', lw=2, label='Theoretical (Change of Variables)')
plt.legend()
Much literature exists that looks at composing transformations for which the Jacobian calculation is fast. One such example are Residual flows [1][2] where the transformation looks like :
\[x_k = f(x_{k-1}) = x_{k-1} + g(x_{k-1})\]The log-determinant of the jacobian looks like :
\[\log | \det \frac{\partial f_{k}(x_{k-1})}{\partial x_{k-1}}| = \log | \det (I + \frac{\partial g(x_{k-1}) }{\partial x_{k-1}})|\] \[= \det | \log (I + \frac{\partial g(x_{k-1}) }{\partial x_{k-1}})|\] \[= \textrm{Tr}( \log (I + \frac{\partial g(x_{k-1}) }{\partial x_{k-1}}))\]From discrete time updates to continuous time updates (Neural Ordinary Differential Equations (NODES))
In the limit of infinite layers or transformations the updates
\[x_k = f(x_{k-1}) = x_{k-1} + g(x_{k-1})\]can be formulated within the framework of NODES (also called as Continuous Normalizing Flows).
\[\frac{dx_t}{dt} = g_{\phi}(x_{t}, t)\]The goal is to train a neural network that can learn this velocity field $g_{\phi}(x_{t}, t)$ which transport points starting from $p_{\rm{prior}}(x_{0}, 0)$ to the desired data distribution $p_{\rm{data}}(.)$. A continuous time variant of the discrete change of variables formula was introduced by Chen et. al.[3] and is referred to as the instantaneous change of variables. It can be derived from the discrete change of variables formula but is a bit involved which is why I recommend the reader to check out the derivation for themselves in Appendix A of the paper [3].
\[\frac{\partial \log p(x_t,t)}{\partial t} = - \nabla_x . g_{\phi}(x_{t}, t)\]The log density of the terminal PDF induced by the neural ODE $ \frac{dx_t}{dt} = g_{\phi}(x_{t}, t) $ is given by
\[\log p(x_T, T) = \log p_{\rm{prior}}(x_0, 0) - \int_0^T \nabla_x . g_{\phi}(x_{t}, t) dt\]which allows one to construct objective functions $\mathcal{L}_{\rm{NODE}} = \mathbb{E}_{x \sim p_{\rm{data}}} [\log p(x_T, T)] $ that maximize the likelihood and generate gradients for updating the model parameters $\phi$. Maximizing $\mathcal{L}_{\rm{NODE}}$ requires backpropogating through the ODE solver. The adjoint sensitivity method computes gradients via an auxiliary ODE with O(1) memory complexity, but NODE training remains expensive due to numerical integration at each step.
The instantaneous change of variables is a special case of the Fokker-Planck equation with $D(x_t, t) = 0$.
\[\begin{align} \frac{\partial p(x_t, t)}{\partial t} &= -\nabla_x . (p(x_t, t)g(x_t, t)) + \nabla_x^2(p(x_t, t)D(x_t, t)) \\ \frac{\partial p(x_t, t)}{\partial t} &= -\nabla_x . (p(x_t, t)g(x_t, t)) \\ \frac{\partial p(x_t, t)}{\partial t} &= -g(x_t, t)\nabla_x p(x_t, t) - p(x_t, t)\nabla_x g(x_t, t) \quad \textrm{(PRODUCT RULE)} \\ \end{align}\]From the chain rule of partial derivatives we can write $\frac{\partial p(x_t, t)}{\partial t}$ as
\[\begin{align} \frac{\partial p(x_t, t)}{\partial t} &= \frac{\partial p(x_t, t)}{\partial x_t}\frac{\partial x_t}{\partial t} + \frac{\partial p(x_t, t)}{\partial t} \\ \frac{\partial p(x_t, t)}{\partial t} &= \frac{\partial p(x_t, t)}{\partial x_t}g(x_t, t) + \frac{\partial p(x_t, t)}{\partial t} \end{align}\]Substituting the product rule in the chain rule we get the instantaneous change of variables formula
\(\frac{\partial p(x_t, t)}{\partial t} = \cancel{g(x_t, t)\nabla_x p(x_t, t)} - \cancel{g(x_t, t)\nabla_x p(x_t, t)} - p(x_t, t)\nabla_x g(x_t, t){\partial t}\) \(\frac{\partial \log p(x_t, t)}{\partial t} = -\nabla_x g(x_t, t)\)
Viewing datapoints as particles
The Langevin equation describes the forces acting on a particle as a sum of a viscous force proportional to the particle's velocity $\gamma v$ and a noise term $dW_t$.
\[m\frac{dv}{dt} = -\gamma v + F(x) + \sigma dW_t\]At equilibrium when the frictional forces $|\gamma v|$ dominate the inertial forces $|ma|$ then we get the overdamped Langevin Equation
\[\begin{align} \gamma \frac{dx}{dt} &= F(x) + \sigma dW_t \\ \frac{dx}{dt} &= \frac{1}{\gamma} F(x) + \frac{\sigma}{\gamma} dW_t \\ \frac{dx}{dt} &= -\frac{1}{\gamma} \frac{dU}{dx} + \frac{\sigma}{\gamma} dW_t \end{align}\]From the Einstein relation $ D = \mu k_B T $ where $\mu $ is the ratio of the particle's terminal drift velocity to an applied force. We can see from the above equation that $\gamma$ is inverse of mobility $\mu$ hence $ D = \frac{k_B T}{\gamma} $. $D$ is also parametrized as $D=\frac{\sigma^2}{2}=\frac{\sigma^2}{2\gamma^2}$ (see Fokker Planck equation) Combining these 2 relationships, we get the well known result from the fluctuation-dissipation theorem $\sigma = \sqrt{2\gamma k_B T}$
\[\frac{dx}{dt} = -\beta D \frac{dU}{dx} + \sqrt{2D} dW_t\]More generally the Itô process describes the flow of a particle $dx(t)$ through a drift term $g(x(t), t)$ and a diffusion coefficient $h(x(t), t)$. The diffusion coefficient modulates a continuous time stochastic process $W(t)$ called the Wiener process (standard Brownian Motion).
\[dx_t = g(x_t, t)dt + h(x_t, t)dW_t\]Gaussian increments : For $ 0<=s<t$ $ w(t) - w(s) = N(0, (t-s)I_{D})$ The increments are independent of the past. The change in the distribution/density of the particles is defined by the Fokker Planck equation :
\[\frac{\partial p(x_t, t)}{\partial t} = - \nabla_x .(p(x_t, t)g(x_t, t)) + \frac{1}{2} \nabla_x^2 p(x_t, t)h^2(x_t, t)\]From the overdamped langevin equation, substituting $\frac{h^2(x_t, t)}{2} = D$ and $g(x_t, t)=-\beta D \nabla U$ we get
\[\begin{align} \frac{\partial p(x_t, t)}{\partial t} &= \nabla_x . (p(x_t, t) \beta D \nabla_x U) + \nabla_x^2 p(x_t, t)D \\ \frac{\partial p(x_t, t)}{\partial t} &= \nabla_x . (p(x_t, t) \beta D \nabla_x U)+ \nabla_x . \nabla_x p(x_t, t)D \\ \frac{\partial p(x_t, t)}{\partial t} &= \nabla_x . (p(x_t, t) \beta D \nabla_x U)+ \nabla_x . (D \nabla_x p(x_t, t) + \cancelto{0}{p(x_t, t) \nabla_x D} ) \\ \frac{\partial p(x_t, t)}{\partial t} &= \nabla_x . (p(x_t, t) \beta D \nabla_x U)+ \nabla_x . D \nabla_x p(x_t, t) \\ \frac{\partial p(x_t, t)}{\partial t} &= \nabla_x . D(\beta \nabla_x U + \nabla_x)p(x_t, t) \end{align}\]The above equation is called the Smolchowski equation. Defining a flow produces a unique density evolution. However, describing a density evolution does not prescribe a unique flow. We will come back to this idea in the Flow Matching section.
Theoretical probability distribution for the Weiner process
\[g(x_t, t) = 0 ; h(t) = 1\] \[\frac{\partial p(x_t, t)}{\partial t} = \frac{1}{2} \frac{\partial^2 p(x_t, t)}{\partial x^2}\]Using initial conditions $p(x, 0) = \delta(x)$ and applying separation of variables we get the following solution :
\[p(x_t, t) = \frac{1}{\sqrt{2\pi t}} e^{\frac{-x^2}{2t}}\]
Lets simulate the weiner process and compare histogram of particle positions to the theoretical distribution obtained from the Fokker Planck equation.
# Examples of particle ODEs
class ParticleODE():
def __init__(self, N, T, dt, seed, process):
self.seed = seed
self.T = T
self.N = N
self.dt = dt
self.process = process
def weiner(self, x):
rng = np.random.default_rng(seed=self.seed)
dW = rng.normal(0, np.sqrt(self.dt), size=self.N)
dx = dW
return dx
def overdamped_langevin(self, x, t, beta=0.2, D=0.2, c=2):
# force = lambda x : 0.2*(x + 0.1) - 0.02*(x - 0.1)**3
dUdx = lambda x : c
dxdt = -beta*D*dUdx(x) + np.sqrt(2*D)*self.weiner(x)
return dxdt
def potential(self, x):
# Double Well potential
# return -0.1*(x + 0.1)**2 + 0.005*(x - 0.1)**4
# Linear potential
return 2*x
def step(self, x):
if self.process == 'weiner':
return self.weiner(x)
elif self.process == 'overdamped_langevin':
return self.overdamped_langevin(x)
else:
raise Exception("Process not Defined !")
T = 3
N = 500
x = np.zeros((N))
dt = 0.1
t = np.arange(0, T, dt)
x_hist = np.zeros((len(t), N))
for i, j in enumerate(t):
particle_ode = ParticleODE(N, T, dt, seed, process='weiner')
x += particle_ode.step(x)
x_hist[i] = x
total_frames = T
samples_per_frame = N
fig, ax = plt.subplots(figsize=(6, 4))
rlim = -5
llim = 5
bin_width = 0.2
bins = np.arange(rlim, llim, bin_width)
# Define the animation function (called sequentially for each frame)
def update(frame):
ax.clear()
# Set static plot limits and labels
ax.set_xlim(rlim, llim)
ax.set_ylim(0, 1)
ax.set_title("Weiner Process")
ax.set_xlabel("Value")
ax.set_ylabel("Density")
ax.grid(True, linestyle="--", alpha=0.6)
current_data_size = samples_per_frame
current_data = x_hist[frame, :]
ax.hist(
current_data,
bins=bins,
density=True,
color="royalblue",
edgecolor="black",
alpha=0.7
)
x_range = np.arange(-5, 5, 0.1)
p = lambda x, t: (1/np.sqrt(4*np.pi*(t+0.0000001)))*np.exp((-x**2)/(4*(t+0.0000001)))
# For the wiener process
ax.plot(x_range, p(x_range, t[frame]), c='orange')
ax.text(
-3.8,
0.45,
f"Total Samples: {current_data_size}",
fontsize=12,
bbox=dict(facecolor="white", alpha=0.8),
)
# Create the animation object
# frames=100 means the update function will be called 100 times
# interval=20 means 20 milliseconds between frames in the live preview
# Omit init_func and set 'blit=False' because ax.clear() redraws everything.
ani = animation.FuncAnimation(
fig, update, frames=len(t), blit=False, interval=20
)
# Save the animation as a GIF using the Pillow writer
# fps=30 means 30 frames per second in the final GIF file
output_filename = "weiner_process.gif"
ani.save(output_filename, writer="pillow", fps=5)
print(f"Animation successfully saved as {output_filename}")
plt.show()
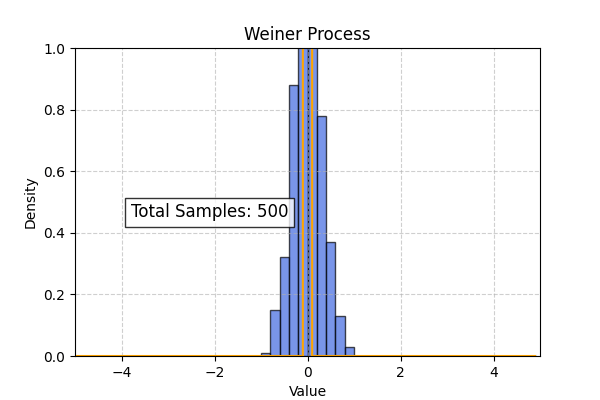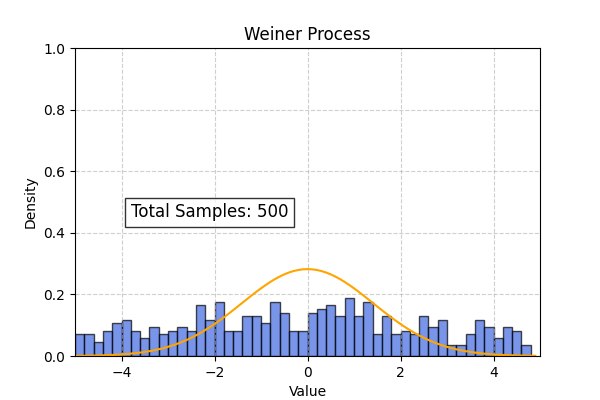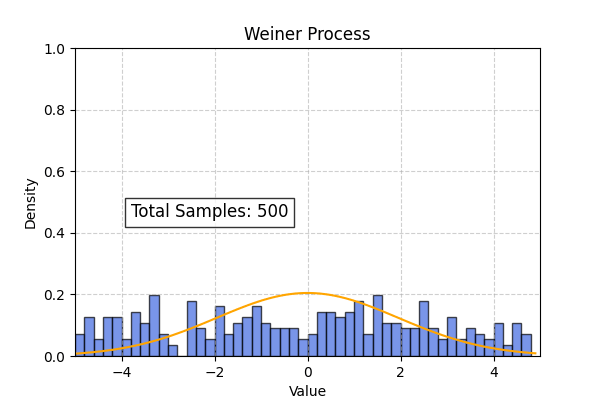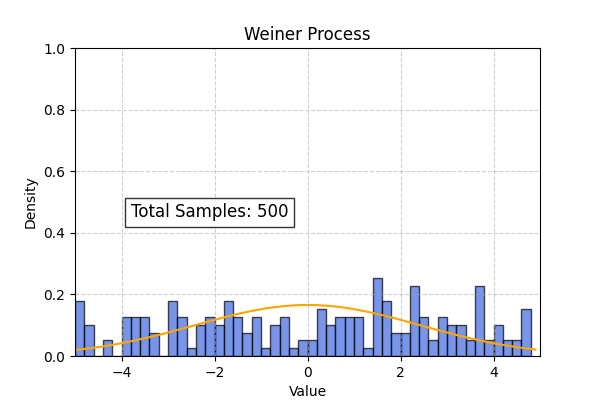
Using the above code we can also simulate the overdamped langevin process. In this case the theoretical distribution computed from the Smolchowski equation is (Ref : Wikipedia)
\[P(x, t | x_0, t_0) = \frac{1}{\sqrt{4\pi D(t- t_0)}} \exp \left[ \frac{-1}{2}\frac{(x - x_0 + D\beta c(t - t_0))^2}{4D(t-t_0)} \right]\]To create the below simulation I used $D=1, \beta=0.2, c=2$
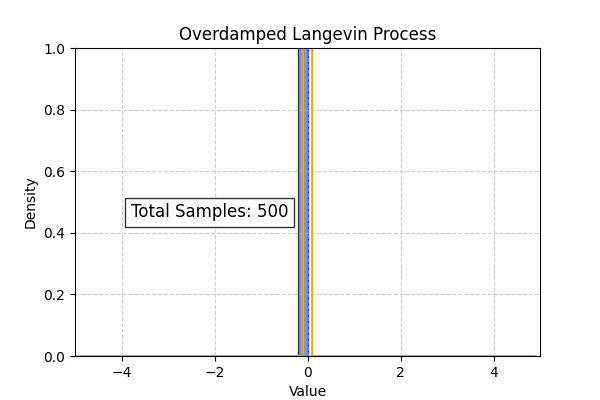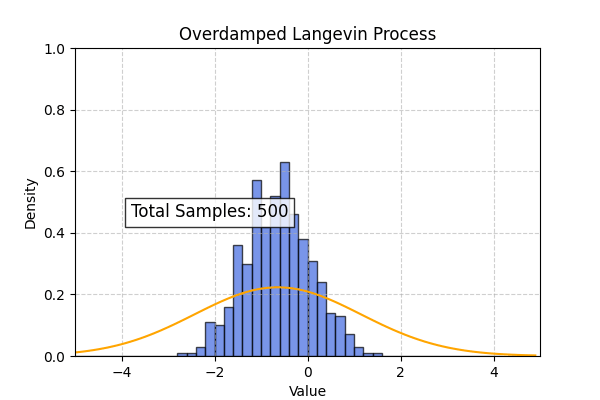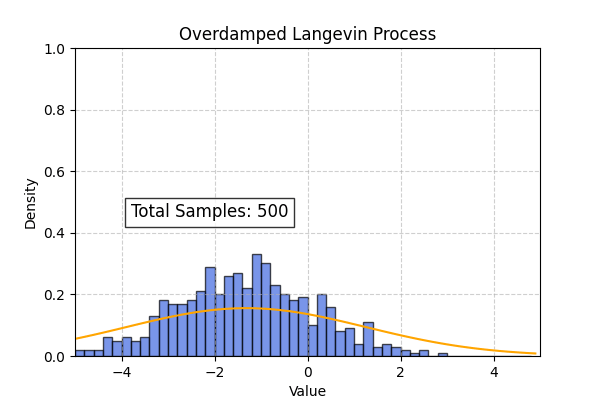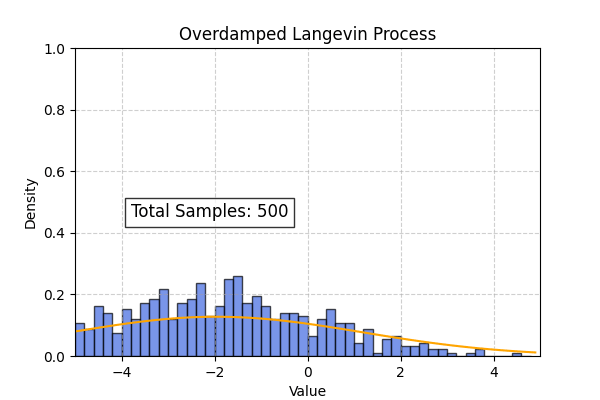
Flow Matching
Will be updated soon !
References
[1] Behrmann, J.; Grathwohl, W.; Chen, R. T. Q.; Duvenaud, D.; Jacobsen, J.-H. Invertible Residual Networks. arXiv 2019 https://doi.org/10.48550/arXiv.1811.00995.
[2] Chen, R. T. Q.; Behrmann, J.; Duvenaud, D.; Jacobsen, J.-H. Residual Flows for Invertible Generative Modeling. arXiv 2020 https://doi.org/10.48550/arXiv.1906.02735.
[3] Chen, R. T. Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D. Neural Ordinary Differential Equations. arXiv 2019 https://doi.org/10.48550/arXiv.1806.07366.